|
|











|
|
|

 |
0 |
|
| View Articles |
|
 |
Name |
| 손병목 |
(2002-03-28 00:25:01, Hit : 45175, Vote : 2188)
|
|
|
| Homepage |
http://www.itmembers.net |
|
| Subject |
오라클 데이터 검색 - ORDER BY, GROUP BY |
|
|
이번 시간에는 데이터 검색에 사용되는 ORDER BY와 GROUP BY 문에 대해 알아보기로 하겠습니다.
ORDER BY와 GROUP BY는 SELECT 문의 말미에 사용되며 검색된 결과를 다시 정렬하거나 그룹으로 묶어서 보여주는 기능을 합니다.

- OREDER BY
SELECT 문으로 검색한 결과를 특정한 컬럼을 기준으로 정렬하여 보여주고자 할 때 사용합니다.
다음과 같은 형식으로 사용합니다.
SELECT 컬럼1, 컬럼2, ...
INTO :변수1, :변수2, ...
FROM 테이블1, 테이블2, ...
WHERE 조건
ORDER BY column1 [asc], column2 desc, column3 ...
여기서 ORDER BY 뒤에 나열한 컬럼 순서대로 정렬됩니다. 즉 column1을 기준으로 먼저 정렬하고 column1의 값이 같을 경우 column2를 기준으로 정렬한다는 뜻입니다.
컬럼 이름 뒤의 asc 또는 desc는 오름차순, 내림차순을 의미합니다. 생략하면 기본적으로 오름차순으로 정렬됩니다.
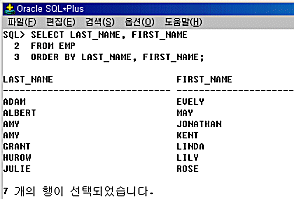 자 다음과 같이 입력하고 그 결과를 확인해 보세요. 자 다음과 같이 입력하고 그 결과를 확인해 보세요.
SELECT LAST_NAME, FIRST_NAME
FROM EMP
ORDER BY LAST_NAME, FIRST_NAME;
위에서 ORDER BY LAST_NAME, FIRST_NAME; 대신
ORDER BY 1, 2;와 같이 써도 됩니다. SELECT 문에서 사용한 컬럼 이름 순서대로 1, 2, 3...과 같이 부여해서 컬럼 이름 대신 숫자로 표시해도 된다는 뜻입니다.
- GROUP BY
SELECT 문으로 검색한 결과를 특정 컬럼을 기준으로 그룹화하여 표시합니다.
여기서 그룹화라는 것은 특정 컬럼의 값이 같을 경우 해당 레코드를 모두 묶어서 하나로 표시한다는 뜻입니다.
먼저 GROUP BY를 사용할 때의 문장 형식은 다음과 같습니다.
SELECT 컬럼1, 컬럼2, 컬럼 함수 ...
INTO :변수1, :변수2, ...
FROM 테이블1, 테이블2, ...
WHERE 조건
GROUP BY 컬럼1, 컬럼2, ...
HAVING 조건
ORDER BY 컬럼1, 컬럼2,
위에서 보는 것과 같이 GROUP BY는 ORDER BY 위에서 사용해야 합니다.
그리고 HAVING 절을 사용할 수 있는데, 뒤에서 다루겠지만 HAVING은 GROUP을 만드는 조건을 나타냅니다.
백문이 불여일견. 일단 봅시다.
먼저 실습을 위해 다음과 DEPT_SALES라는 테이블을 하나 만들어야겠네요.
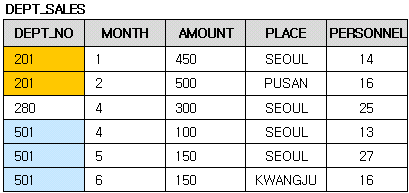
위에서 보면 DEPT_NO가 중복되는 레코드가 있죠?
그래서 지금 실습할 내용은 DEPT_NO가 중복되는 것끼리 묶어서(그룹화하여) AMOUNT의 평균을 구하는 것입니다. 즉 DEPT_NO가 201인 것의 AMOUNT 평균, 280의 평균, 501의 평균을 구하는 것이 목적입니다.
그러기 위해서 먼저 테이블을 만들어야겠죠.
아래의 코드를 복사하여 그대로 사용하시면 됩니다.
DROP TABLE DEPT_SALES;
CREATE TABLE DEPT_SALES
( DEPT_NO CHAR(3),
MONTH CHAR(2) NOT NULL,
AMOUNT NUMBER NOT NULL,
PLACE VARCHAR2(20),
PERSONNEL CHAR(2),
CONSTRAINT PK_DEPTNO_MONTH PRIMARY KEY(DEPT_NO, MONTH)
);
INSERT INTO DEPT_SALES VALUES ('201', '1', 450, 'SEOUL', '14');
INSERT INTO DEPT_SALES VALUES ('201', '2', 500, 'PUSAN', '16');
INSERT INTO DEPT_SALES VALUES ('280', '4', 300, 'SEOUL', '25');
INSERT INTO DEPT_SALES VALUES ('501', '4', 100, 'SEOUL', '14');
INSERT INTO DEPT_SALES VALUES ('501', '5', 150, 'SEOUL', '27');
INSERT INTO DEPT_SALES VALUES ('501', '6', 150, 'KWANGJU', '16');
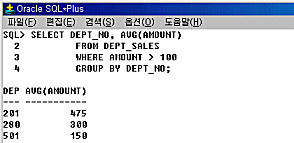 이제 위에서 얻고자 하는 결과를 구하기 위해 다음과 같이 쿼리문을 작성합니다. 이제 위에서 얻고자 하는 결과를 구하기 위해 다음과 같이 쿼리문을 작성합니다.
SELECT DEPT_NO, AVG(AMOUNT)
FROM DEPT_SALES
WHERE AMOUNT > 100
GROUP BY DEPT_NO;
위의 문장을 이해하셨다면, 문제 하나 내겠습니다.
지역(PLACE)별로 그룹화하여 지역별 AMOUNT의 평균을 구해보세요. 단, 지역명의 역순으로 정렬하세요.
해답을 보시려면 아래 빈곳을 마우스로 드래그해보세요.
SELECT PLACE, AVG(AMOUNT)
FROM DEPT_SALES
GROUP BY PLACE
ORDER BY PLACE DESC;
- HAVING 절
HAVING 절은 반드시 GROUP 절과 함께 사용됩니다.
SELECT 문의 일반적인 조건이 WHERE 절에서 표시한다면, GROUP 절에 대한 조건은 HAVING 절에 씁니다.
예를 들어,
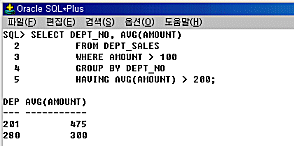 SELECT DEPT_NO, AVG(AMOUNT) SELECT DEPT_NO, AVG(AMOUNT)
FROM DEPT_SALES
WHERE AMOUNT > 100
GROUP BY DEPT_NO
HAVING AVG(AMOUNT) > 200;
위의 문장은 AMOUNT가 100을 초과하는 것 중에서 DEPT_NO를 기준으로 그룹화하되, 그룹화한 AMOUNT의 평균이 200을 초과하는 것만 표시하라는 뜻입니다.
이번 시간에는 딱 두가지 - ORDER BY와 GROUP BY에 대해 알아보았습니다. 그리고 GROUP BY는 별도의 조건절인 HAVING 절을 사용할 수 있다는 것도 알았습니다.
다음 시간에는 여러 테이블을 대상으로 데이터를 검색하기 위해 JOIN과 UNION 명령에 대해 알아 보겠습니다.
벌써 목요일 새벽입니다.
대개 한주의 피로를 가장 많이 느끼는 날이죠. 화이팅! 힘냅시다.
이상 동주아빠 손병목이었습니다.

|
|
|
|
|
|